
如果我来做简书运营……
作为一个前产品狗和半个互联网研究者,以及当前简书深度使用者,想谈谈我眼中的简书运营如何做,目的只是为了提供一家之言,仅供参考。 2010年被称为“微博元年”,在此之前,我是一个深度的博客使用者,从使用博客大巴等产品,到自建个人博客网站。那时… 阅读更多 »如果我来做简书运营……
作为一个前产品狗和半个互联网研究者,以及当前简书深度使用者,想谈谈我眼中的简书运营如何做,目的只是为了提供一家之言,仅供参考。 2010年被称为“微博元年”,在此之前,我是一个深度的博客使用者,从使用博客大巴等产品,到自建个人博客网站。那时… 阅读更多 »如果我来做简书运营……
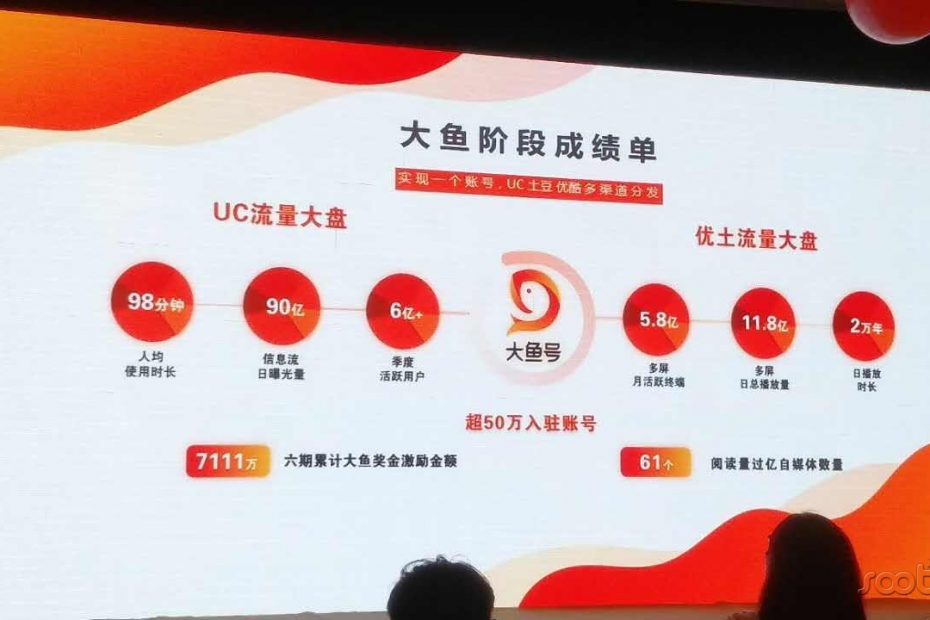
在简书写作一段时间后,自觉的可以毕业了,于是就注册了几大号,头条号、公众号,还有BAT各自的百家号、大鱼号和企鹅号。而在运营了一个月左右后却发现这些号大都是陷阱,现将经验分享一下。 大鱼号 几大号都蛮好顺利通过申请的,其中最早转正的就是阿里… 阅读更多 »自媒体写作平台多是陷阱:BAT各号运营一个月后的感受

图片发自简书App 在简书写作也有段日子了,从开始的无人问津,到现在几乎篇篇推首,也给了我继续写作下去的动力。 也激励了我去尝试开通其他自媒体平台的勇气。这里将自己的心得和运营几个平台的经验分享一下,也鼓励一下坚持在简书写作的朋友。 简书:… 阅读更多 »只用简书15篇文章15天头条号转正
原来用的是MT系统,换服务器后觉得建MT很麻烦,于是转投到WP门下。因为原来的MT站已经停掉,域名也已经转向,所以没法到处Feed,幸好在Blogbus上有备份。

今天在饭馆吃面时,一美女(美国女人)手拿亚马逊的Kindle玩,忍不住心动。以我向来不主动和老外搭讪的作风,这次她既然送上门了,那么俺就主动问候一下。
Dreamhost的服务器到期了,续费要$120,于是决定换服务器。起初选择的是Bluemonster的空间,一年$72。付款后发现其Cpanel(后台管理面板)在大陆无法登陆,于是只好当日再退款后,选择了IXWebhosting的服务器。Bluemonster退款很迅速,很快就受到银行的退款短信。这一点比Dreamhost要好,现在还未收到退款,问了客服说要我自己问问银行,他们已经做了refund处理。
Google终于下定决心放弃中国市场了。或许当初就不该来这里,冒着背弃自己企业精神“不作恶”的信条,当初引起了多少网民的争议,原来Google也不能背离资本的逻辑。
现在Google决定走了,却迎来了一片掌声。在中国的跨国公司或许应该学习。

上篇博文只是翻译自国外的一篇书评,又是在评价另一本在国外所出版的书籍。似乎根本无关乎中国政治,发在豆瓣上时就以莫须有的理由被删除了。

微软,给予了我们很多,但却限制我们走的更远。抛弃他,跟着Google轻装上阵。
我博客上的一篇书评被自动加锁了,无法呈现在博客前台。这是Blogbus最近调整“写博客”功能的后果,它引入了关键词封锁技术,与先前将某些关键词打星号相比,的确“进步”了不少,而且能在“有害”的文章发布之前就将他屏蔽掉,让人不得不气愤。询问管理员,得到的回复是替换掉关键词就好了,但问题是,我怎么知道那些是你们所谓的“关键词”呢?任何法律和法规也没有给我提供这样一张不能言说的“关键词清单”。
原有的华硕本本才100G的硬盘,只能存储些资料。前两天在太平洋数码花了500大洋买了个日立 Neso 320G移动硬盘,回来查了一下网上报价,发现整整贵了50块。此话不提。
在dreamhost的主机上安装了wordpress mu,完成后测试新用户注册,发现邮箱里收不到注册激活的邮件,于是就在网上找了这篇文章:解决wordpress mu 收不到邮件问题
网站定位
以汽车为主题的sns社区。仿照现实中的情景为用户提供买车、保养、修车体验,附加提供用户合伙经营等体验。
古语有云:工欲善其事、必先利其器…于是乎,就为了写论文,俺这一个月来不思劳顿辛苦、以及不分昼夜黑白地做了个能帮助写论文的网站。当然不是那种比如你输入个题目它就自动给生成一篇论文的全自动化生产线。

最近频频收到豆瓣解散小组的通知,有如下:
政治哲学 Political philosophy小组
南方周末“自由谈”读友会小组(被解散两次)
黑色幽默(Black humor)小组
NZ小组。。。
“WIKINDX 是一個個人或多人使用的參考書目環境,儲存了可以搜尋的參考資料、備註與引用文章,整合所見即所得編輯器來編輯文章,文章也會自動格式化為指定的引用風格。”
第一步:你得先在脑中做一个整体规划
做了一个简单的使用豆瓣Api查询书籍的信息。代码如下,将其存为如douban.php文件,然后运行。本地测试我使用的是wamp server2。
长时间,豆瓣的主页上都没有了去往9点的链接。以为豆瓣放弃了RSS的竞争而去做什么“广场”的东东。
今天,打开豆瓣发现栏目上出现了醒目的去往9点的箭头。
一向号称最懂中文的百度,也最懂国情,在关键词屏蔽上跟D中央紧紧保持一致。
而近日,央视罕见地在“新闻30分”连续报道了百度竞价排名的运作内幕,详见: